杠杆炒股,股票融资!

主要的云构建商尽头超大范围提供商(在许厚情况下,一家公司既充任云提供商又充任超大范围提供商)在部署 AI 测验平台时作念出了我方的本领选拔。他们齐使用 Nvidia 数据中心 GPU,若是有的话,还会使用他们我方拓荒的 XPU 加快器。如今,他们无意可能会使用 AMD GPU。
除了少数例外,东说念主工智能测验完全是对于接洽和拓荒的,既包括东说念主工智能模子,也包括诈欺这些模子的家具,而且由于时间至关热切,财富似乎不是问题,这些公司很难选拔第三种选拔。(至少四十年来,宇宙上顶级的政府资助的 HPC 中心一直齐是这种情况。)
在云构建者和超大范围企业中,很难打入 AI 测验范畴,这亦然为什么尽管 Nvidia GPU 匮乏,但宇宙上好多 AI 芯片初创公司仍未诈欺其芯片和软件堆栈在系统销售方面引起震憾的原因之一。但这些初创公司(其中 Cerebras Systems、SambaNova Systems 和 Groq 是热切的几家)当前认为,他们有契机修复硬件业务(无论是通过径直系统销售,仍是通过云录用模式下的租出),因为压力正在转向 AI 推理。
事实上,数据中心的 AI 推理资本腾贵,是企业推出 GenAI 以增强现存应用要津或创建全新应用要津的主要制约成分。莫得东说念主真的知说念异日几年全球 IT 商场可能浪掷若干推贤慧商,但寰球一致认为,这将是进行 AI 测验所需的野快慰装基数的数倍。可能是 3 倍、4 倍,或 10 倍或更多。越来越多的东说念主认为,推理的资本(即生成 token 而不是构建不错生成 token 的模子)必须低得多,但必须使用很是重荷的硬件来完成,而不是一些不错放在铅笔橡皮擦终局的 50 好意思元推理芯片,况且不错在锻真金不怕火的半导体工艺上批量坐褥,封装需求适中。
研讨到统统这些法规,裁汰推理资本是一项忙碌的任务。但若是 GenAI 要隆盛发展,就必须这么作念。这个比例弗成是需要 8,000 个 GPU 来测验一个模子,然后需要 8 或 16 个 GPU 以 200 毫秒的东说念主类眨眼速率进行推理。(早期的 GPT-4 变体便是这种情况。)当前,咱们最多需要 24,000 到 32,000 个 GPU 来测验,需要 16 个或 32 个 GPU 来进行推理,而业界正朝着单个系统中 50,000 或 64,000 或 100,000 个 GPU 的宗旨发展(无意越过多个数据中心以至多个区域),这意味着需要 32 个到 96 个 GPU 来对反馈时间为 200 毫秒的最大模子进行推理。
根据推理图像大小的外传字据,该比率内容上正在变得更好。但这还不足以对 AI 推理的资本产生要紧影响。推理容量可能是测验容量的 10 倍,但需要低廉几个数目级才调获取需求的弹性可膨胀性,从而结束宽泛摄取。
一个八 GPU 节点的价钱约为 40 万好意思元,推理所需的资金将马上增多。若是当前全宇宙少见百万个数据中心 GPU 进行 GenAI 测验,而在不久的将来将需要数千万个 GPU,那么咱们将需要数亿个 GPU 进行推理。理由理由的是:若是 AI 推理的资本是其十分之一,而销售的容量是其十倍,那么产生的收入将是 AI 测验的 1 倍。这对咱们来说意味着 AI 推理的利润远不足 AI 测验,因为每个东说念主齐在拚命收货。
就咱们而言,AI 推理尚无定论,而且仍有可能大量推理仍停留在张量驱动的 CPU 上。咱们多年来一直在说这个,到当前为止,咱们认为这很愚蠢,因为第一轮 GenAI 齐备不是这种情况。然而,咱们一直在驳斥永久目的。
与此同期,AI 芯片初创公司正在转向推理,他们齐但愿将以雷同云的现象租用容量的客户编削为系统买家。若是咱们处于这些新贵的位置,咱们也会作念不异的事情。
日夜不断的 Groq
数据中心推理之战于客岁秋天认真拉开帷幕,Groq 向 Nvidia 的 GPU 发起了挑战。正如 Groq 斡旋独创东说念主兼首席实行官 Jonathan Ross 所评释注解的那样,在此之前,AI 模子还不够大,它们的推贤慧商不足以消灭 GPU。但跟着 GPT-3 和 GPT-4 尽头 GenAI LLM 同类家具的推出,情况已不再如斯。当前,AI 推理变得像十年前的 AI 测验一样成问题,就在 15,000 家初创公司和超大范围企业试图将其交易化时,经济效益运编削得分歧理。
因此,Groq 摄取了两块多少许的 GroqChips(悉数 576 个谈话处分单位,炒期货无意也被称为 LPU),并将它们串联起来运行 Llama 2 70B 推理。这些 LPU 的理由理由之处在于它们不使用 HBM,也不需要台湾半导体制造公司的 CoWoS 中介层。GroqChips 还摄取尽头锻真金不怕火的 14 纳米工艺蚀刻而成,这意味着它们不错以低资本制造。
无论如何,Groq 暗示,这个强大的系统每秒不错处分 315.06 个token。那时,罗斯暗示,典型的 Nvidia DGX H100 系统每秒推送 10 个到 30 个tokens就算庆幸了。(咱们不知说念罗斯在 Nvidia 机器上驳斥的量化级别和数据分辩率是什么。)Groq 宣称其系统以十分之一的资本运行推理的速率晋升了 10 倍,或者性价比晋升了 100 倍。(咱们锋利怀疑这是使用 Groq 和其他云为推理管事提供的云 API 管事的资本,而不是底层系统的资本。)
两周前,Cerebras 在其 CS-2 晶圆级平台上通知了我方的推理套件;到当前为止,该公司只认真销售用于测验的机器,事实上,本年 3 月,该公司刚刚通知与高通配合拓荒推理野心 Sidecar。家具和策略高等副总裁 Andy Hock 向咱们先容了推理管事的数据。
Cerebras 以 FP16 分辩率运行其模子权重,而不是将其裁汰到 FP8、MX6、MX4 或 FP4 分辩率,这会扬弃模子的一些质料以交流更高的微辞量。
以下是 Cerebras 使用 Llama 3.1 8B 模子对四晶圆系统与 Groq 集群以及在多样云中运行的一堆单个八路 H100 节点进行测量的要领:
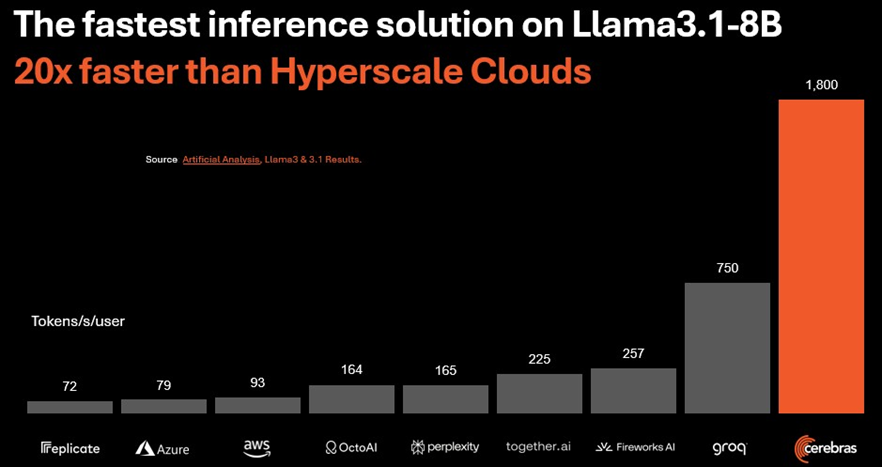
上图中的数据来自孤苦基准测试公司 Artificial Analysis。
跟着 LLM 中参数数目的增多,模子变得愈加密集,况且必须通过更多的权重来传输数据,因此微辞量下落:
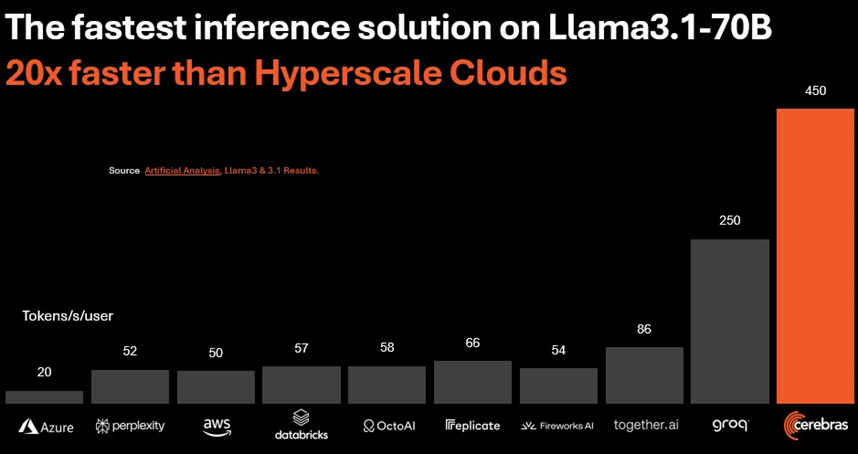
Cerebras 在四晶圆机上阐扬出的性能(需要有实足的 SRAM 来加载模子权重和防备键值)是云 LLM API 的 20 倍,比在云上运行的最好 DGX H100 好 5 倍独揽。据咱们所知,莫得与多节点 HGX 或 DGX 系统进行比较,这似乎不刚正。
Cerebras 正在为 Llama 3.1 405B 模子以及 Mistral Large 2、OpenAI Whisper 和 Cohere Command R LLM 实施其推理管事。
Cerebras 对其推理管事的收费现象如下:

跟着模子的参数数目赓续增多,需要更多内存和更多处分,输入和输出tokens的资本也会跟着每个“实例”的微辞量下落而高潮。Cerebras 为这两种模子提供免费套餐,每分钟最多 30 个恳求,每天最多 100 万个tokens。
趁机说一句,Cerebras 宣称 Groq 对其 Llama 3.1 70B 型号收取每百万代币 64 好意思分的用度,况且它使用 8 位精度而不是 16 位精度,以达到每位用户每秒 250 个代币。Cerebras 以 16 位分辩率为每位用户提供每秒 450 个代币,资本为每百万代币 60 好意思分。这意味着每位用户的微辞量是原本的 1.8 倍,精度是原本的 2 倍,资本略低。
当前,SambaNova 也运转涉足推理范畴,其 SambaNova Cloud 上公布了 Llama 3.1 基准测试效用。该公司还为该管事提供免费、拓荒者和企业级管事,该管事运行在配备 SN40L 可重构数据单位的机器上,该单位于一年前推出。
SambaNova 家具副总裁 Anton McGonnell 向咱们堤防先容了其系统(建立了 16 个 RDU)在 Artificial Analysis 运行的 Llama 3.1 基准测试中的阐扬。
在 Llama 3.1 8B 型号上,SambaNova 机器好像以全 BF16 精度每秒处分 1,100 个tokens。看起来这些不是多个用户的批量效用,而是让每个用户走访齐备的 16 个 RDU,以在最短的时间内完成 LLM 的查询。在 Llama 3.1 70B 型号上,McGonnell 揣摸峰值性能将在每秒 580 个tokens独揽,而东说念主工分析的最终效用将在每秒 500 个tokens独揽,因为 SambaNova 进行了优化,使其更接近峰值性能。
在 Llama 3.1 405B 型号上,Artificial Analysis 测量的峰值性能为每秒 132 个tokens,这远远越过了为 Llama 3.1 型号提供 API 走访的云 Hopper 实例。请看一看:
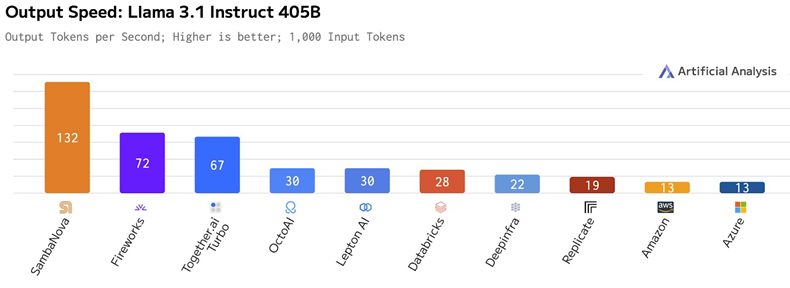
SambaNova Cloud 的免费层和企业层推理现已推出;拓荒者层的用度可能与企业层比较象征性地低一些,但好像处分比免费层更多的tokens并托管更多用户。(咱们不知说念免费层的法规。)
然而咱们照实知说念企业级输入和输出tokens的羼杂价钱。对于 Llama 3.1 8B,每 100 万个tokens的价钱为 12 好意思分。对于 Llama 3.1 70B 型号,正如咱们所说,它的密度要大得多,价钱高潮到每 100 万个tokens 70 好意思分。这意味着参数数目增多了 8.75 倍,但每 100 万个tokens的资本仅增多了 5.8 倍。对于 Llama 3.1 405B 型号,每 100 万个tokens的价钱为 6 好意思元,这意味着参数数目比 70B 型号增多了 5.8 倍,每 100 万个tokens的资本增多了 8.6 倍。
云 LLM API 是真实存在的。若是这是 Groq、Cerebras 和 SambaNova 从初创公司和着实的企业那边获取资金的唯独路线,而这些企业但愿以比使用 GPU 少得多的钱(但不一定更少的硬件)进行 AI 推理,那么他们无疑会很乐意收受这些资金。但咱们认为这些管事是试图销售硬件的亏损销售。数据和模子主权不仅适用于国度政府 - 它们适用于统统东说念主,咱们认为将 GenAI 插足坐褥的组织不会急于将其数据和模子存放在超大范围或云构建器中。
这对销售 AI 野心引擎的统统东说念主而言齐是好音信,包括 Nvidia、AMD,从永久来看,可能还包括英特尔。因为超大范围企业和云构建者正在制造我方的 AI 加快器,他们从 GPU 中获取无数利润,况且可能会尝试用他们的 AI 加快器作念不异的事情。
临了一件事:使用单个用户或批量用户进行我方的基准测试,并测试统统这些内容。然后从供应商那边获取内容的系统硬件价钱,望望装置我方的硬件是否不错省钱 - 以及省若干钱。掌控我方的气运,即使前端更难。
参考衔尾
https://www.nextplatform.com/2024/09/10/the-battle-begins-for-ai-inference-compute-in-the-datacenter/